WAEによるサンプリング
ワーカーズアナリティクスエンジンは、大量のデータを書き込み、迅速に取得する能力を提供し、最小限のコストまたは無コストで実現します。合理的なコストで大量のデータを書き込むために、ワーカーズアナリティクスエンジンは加重適応サンプリング ↗を採用しています。
サンプリングを利用する際、データセットに関する質問に答えるために、すべてのデータポイントが必要なわけではありません。十分に大きなデータセットの場合、必要なサンプルサイズ ↗は元の母集団のサイズに依存しません。必要なサンプルサイズは、測定の分散、分析するサブグループのサイズ、および推定の精度に依存します。
アナリティクスエンジンにとっての意味は、非常に大きなデータセットをはるかに少ない観測値に圧縮できるが、それでもほとんどのクエリに非常に高い精度で答えることができるということです。これにより、無限のカーディナリティを持つ非常に高い使用率を測定できる分析サービスを、低く予測可能な価格で提供できます。
サンプリングの仕組みは高レベルで次のようになります:
- 書き込み時に、データポイントが1つのインデックスに対して非常に迅速に書き込まれる場合、サンプリングを行います。
- クエリが非常に複雑な場合、クエリ時に再度サンプリングを行います。
次のセクションでは、以下のことを学びます:
- サンプリングの仕組み。
- サンプリングされたデータの読み方。
- データがどのようにサンプリングされるか。
- 適応ビットレートサンプリングの仕組み。
- データが使用可能な方法でサンプリングされるようにインデックスを選択する方法。
Cloudflareのデータサンプリングは、Googleマップのようなオンラインマッピングサービスが異なるズームレベルでマップをレンダリングする方法に似ています。大陸全体の衛星画像を表示する際、マッピングサービスはユーザーの画面とインターネット速度に基づいて適切なサイズの画像を提供します。
![]()
マップ上の各ピクセルは、数平方キロメートルなどの大きな面積を表します。ユーザーがスクリーンショットを使用してズームインしようとすると、結果の画像はぼやけてしまいます。代わりに、マッピングサービスはユーザーが特定の都市をズームインするときに高解像度の画像を選択します。ピクセルの総数は比較的一定ですが、各ピクセルは今や数平方メートルのような小さな面積を表します。
![]()
重要な点は、マップの品質は解像度や各ピクセルが表す面積だけに依存しないということです。最終的なビューをレンダリングするために使用されるピクセルの総数によって決まります。
マッピングサービスが解像度を処理する方法とCloudflareアナリティクスが適応サンプルを使用してアナリティクスを提供する方法には類似点があります:
- データの保存方法:
- マッピングサービス:異なる解像度で保存された画像。
- Cloudflareアナリティクス:異なるサンプルレートで保存されたイベント。
- ユーザーにデータを表示する方法:
- マッピングサービス:特定の画面サイズに対してピクセルの総数はほぼ一定で、選択されたエリアに関係なく。
- Cloudflareアナリティクス:データセットのサイズや選択された期間に関係なく、各クエリに対して同様の数のイベントが読み取られます。
- 解像度の選択方法:
- マッピングサービス:各ピクセルが表す面積は、レンダリングされるマップのサイズに依存します。ズームアウトしたマップでは、各ピクセルがより大きな面積を表します。
- Cloudflareアナリティクス:結果の各イベントのサンプル間隔は、基礎となるデータセットのサイズと選択された期間に依存します。大きなデータセットや長い期間にわたるクエリの場合、各サンプリングされたイベントは多くの類似イベントを代表することがあります。
クエリを効果的に書き込み、データを分析するためには、まずワーカーズアナリティクスエンジンでサンプリングされたデータがどのように読み取られるかを学ぶことが役立ちます。
ワーカーズアナリティクスエンジンでは、すべてのイベントが_sample_intervalフィールドで記録されます。サンプル間隔はサンプルレートの逆数です。たとえば、1%のサンプルレートが適用される場合、sample_intervalは100に設定されます。
マッピングの例を使って簡単に説明すると、サンプル間隔は特定のサンプリングされたデータポイント(ピクセル)が表す「未サンプリングデータポイントの数」(キロメートルまたはメートル)を表します。
サンプル間隔は、ワーカーズアナリティクスエンジンに保存されている各行に関連付けられたプロパティです。公平なサンプリングの実装により、サンプル間隔は各行で異なる場合があります。そのため、データをクエリする際には、サンプル間隔フィールドを考慮する必要があります。クエリ結果に定数のサンプリングファクターを単純に掛けるだけでは不十分です。
以下は、サンプリングされたデータに対する一般的なクエリを表現する方法のいくつかの例です。
| 使用例 | サンプリングなしの例 | サンプリングありの例 |
|---|---|---|
| データセット内のイベントをカウント | count() | sum(_sample_interval) |
| 量を合計する(たとえば、バイト) | sum(bytes) | sum(bytes * _sample_interval) |
| 量の平均を計算 | avg(bytes) | sum(bytes * _sample_interval) / sum(_sample_interval) |
| 分位数を計算 | quantile(0.50)(bytes) | quantileWeighted(0.50)(bytes, _sample_interval) |
結果の精度は、前述のマッピングのアナロジーと同様に、サンプル間隔によって決まるわけではありません。高いサンプル間隔でも正確な結果を提供できます。代わりに、精度はクエリされたデータポイントの総数とその分布に依存します。
各イベントのサンプル間隔を決定するために、ほとんどのアナリティクスには、正確な結果で分析する必要がある重要なタイプのサブグループがあります。たとえば、特定のホスト名へのユーザーの使用状況やトラフィックを分析したい場合があります。アナリティクスエンジンのユーザーは、イベントを書き込む際にindexフィールドを埋めることで、これらのグループを定義できます。これにより、指定されたグループ内でよりターゲットを絞った正確な分析が可能になります。
次の観察は、これらのインデックス値には書き込まれるイベントの数が非常に異なる可能性があるということです。実際、ほとんどのウェブサービスの使用はパレート分布 ↗に従い、上位の数人のユーザーが使用の大部分を占めることを意味します。パレート分布は一般的で、次のようになります:
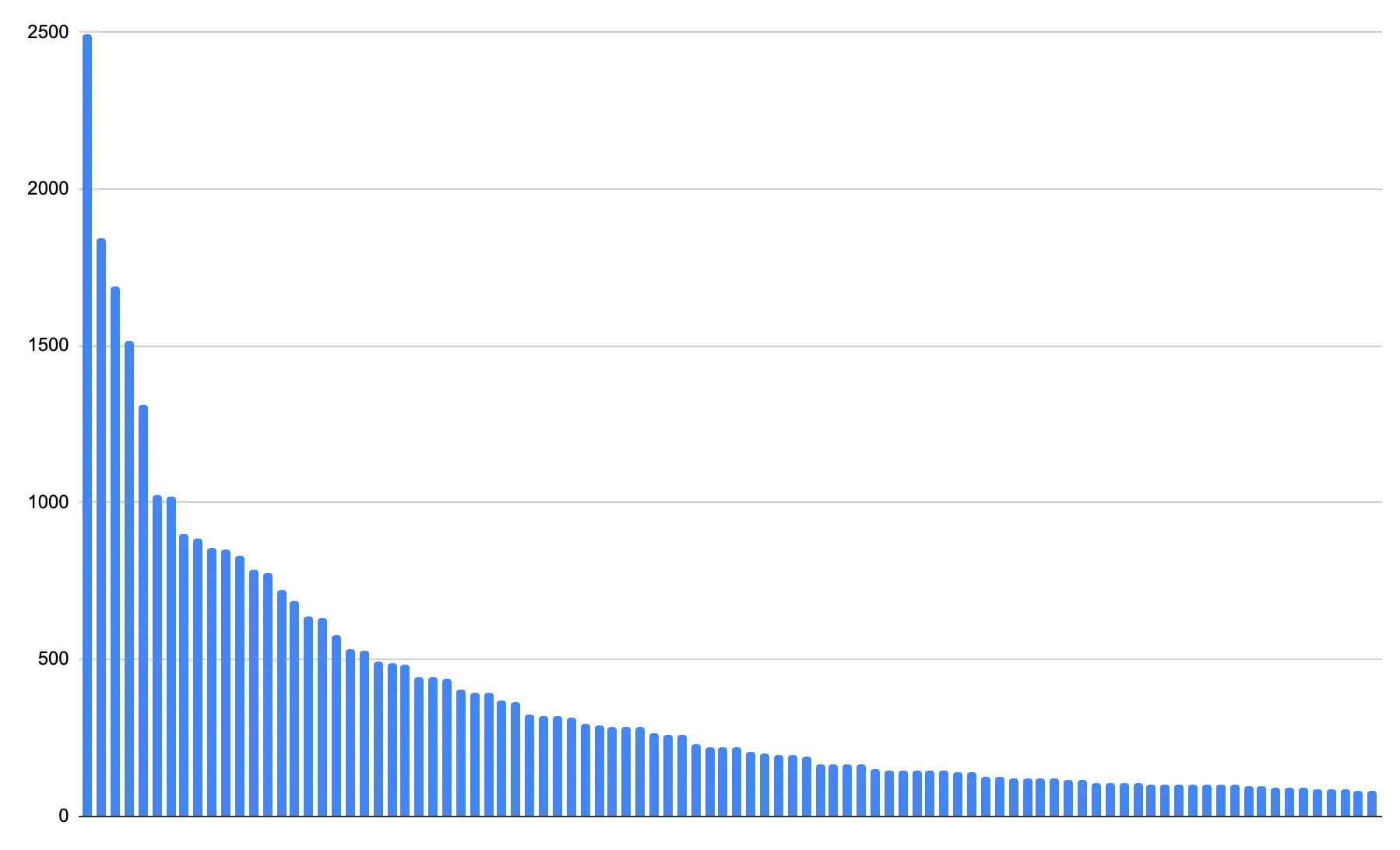
このデータの1%の単純無作為サンプル ↗を取得し、それを全体の母集団に適用すると、最大の顧客を正確に追跡できるかもしれませんが、小さな顧客が何をしているかの可視性を失うことになります:

大きなバーはほとんど変わらないように見えますが、それでもかなり正確です。しかし、小さな顧客を分析すると、結果が量子化 ↗され、完全に0に丸められることさえあります。
これは、1%またはそれ以下の大規模な母集団のサンプルが十分である場合がある一方で、小さな母集団の正確な結果を得るためには、より大きな割合のイベントを保存する必要があることを示しています。
これを実現するために、公平なサンプリングと呼ばれる技術を使用します。これは、各ユニークなインデックス値に対して保存するイベントの数を均等にすることを意味します。比較的珍しいインデックス値の場合、writeDataPoint()を介して取得したすべてのデータポイントを書き込むことがあります。しかし、単一のインデックス値に多くのデータポイントを書き込むと、サンプリングを開始します。
以下は、同じ分布ですが、公平なサンプリングが適用された(シミュレーション)ものです:

このグラフィックは最初のグラフと非常に似ていることに気付くかもしれません。しかし、全体として保存するデータは<10%で済みます。サンプルレートは実際には大きな系列に対して10%よりもはるかに低く(つまり、より大きなサンプル間隔を保存します)、小さな系列に対してはサンプルレートが高くなります。
上記のマッピングのアナロジーを参照してください。表示されるマップのエリアに関係なく、マップ内のピクセルの総数は一定です。同様に、各インデックス値に対して同様の数のデータポイントを常に保存したいと考えています。ただし、マップの解像度 — 各ピクセルが表す面積 — は表示されるエリアに基づいて変わります。同様に、ここでも、保存された各データポイントが表すデータの量は、インデックス内のデータポイントの総数に基づいて変わります。
公平なサンプリングは、特定の時間枠内で各インデックスに対して等しい量のデータが維持されることを保証します。ただし、クエリはターゲットとする時間の長さが大きく異なる場合があります。あるクエリは10分のデータスナップショットのみを必要とするかもしれませんが、他のクエリは10週間にわたるデータを分析する必要があるかもしれません — これは10,000倍長い期間です。
この問題に対処するために、適応ビットレート ↗(ABR)と呼ばれる方法を採用しています。ABRを使用すると、長い時間範囲をカバーするクエリは、より高いサンプル間隔からデータを取得し、固定の時間制限内で完了できるようになります。簡単に言えば、マッピングのアナロジーにおける画面サイズや帯域幅が固定リソースであるのと同様に、クエリを完了するために必要な時間も固定です。したがって、関与するデータの量に関係なく、クエリに対する回答を提供するためにスキャンされる行の総数を制限する必要があります。これにより、公平性が確保されます:基礎となるデータセットのサイズに関係なく、すべてのクエリが利用可能な計算時間の同等のシェアを受け取ることを保証します。
これを実現するために、均等にサンプリングされたデータから派生した異なる解像度(たとえば、100%、10%、1%)でデータを保存します。クエリ時には、クエリの複雑さに基づいて最も適切なデータ解像度を選択します。クエリの複雑さは、取得する行の数と、指定されたN秒の時間制限内でクエリが完了する確率によって決まります。適切な解像度を動的に選択することで、クエリのパフォーマンスを最適化し、割り当てられた時間予算内に収めることができます。
ABRは、データのサイズや時間範囲に関係なく、固定のクエリ予算内で一貫してクエリ結果を提供できるという大きな利点を提供します。これにより、大規模なデータセットを扱う際にタイムアウト、エラー、または高コストに苦しむシステムとは異なります。
サンプリングされたデータで正確な結果を得るためには、インデックスとして使用する適切な値を選択してください。インデックスは、ユーザーがデータをクエリし、表示する方法に一致する必要があります。たとえば、ユーザーが特定のデバイスやホスト名に基づいてデータを頻繁に表示する場合は、それらの属性をインデックスに組み込むことをお勧めします。
インデックスには、インデックスを選択する際に考慮すべき以下のプロパティがあります:
- インデックス値全体にわたってデータセット全体の正確な要約統計を取得します。
- インデックスのユニークな値の数を正確にカウントします。
- 特定のインデックス値内で正確な要約統計(たとえば、カウント、合計)を取得します。
- インデックスに含まれていない特定のフィールドの
Top N値を表示します。 - ほとんどのフィールドでフィルタリングします。
- 分位数のような他の集計を実行します。
考慮すべき制限やトレードオフには以下があります:
- インデックスに含まれていないフィールドの正確なユニークカウントを取得できない場合があります。
- たとえば、
hostnameでインデックスを作成した場合、ユニークなURLの数をカウントできないかもしれません。
- たとえば、
- インデックスに含まれていない非常に珍しい値を観察できない場合があります。
- たとえば、ホストに対する特定のURLが、ホストでインデックスを作成し、数百万のユニークなURLを持つ場合。
- 複数のインデックスにまたがる正確なクエリを一度に実行できない場合があります。
- たとえば、1つのホストのクエリのみを実行できるか、すべてのホストを実行できるかのいずれかで、正確な結果を期待します。
- 特定の個々のレコードを取得できる保証はありません。
- イベントの正確なシーケンスを再構築できるとは限りません。
ほとんどのユースケースでは、各行にユニークなインデックス値(UUIDのような)を書き込むことはお勧めしません。これにより、個々のデータポイントを非常に迅速に取得することは可能ですが、集計や時系列のクエリのほとんどが遅くなります。
ワーカーズアナリティクスエンジンのFAQを参照して、サンプリングに関する一般的な質問を確認してください。