R2を使用して微調整されたOpenAIモデルを作成する
このチュートリアルでは、OpenAI ↗ APIとCloudflare R2を使用して、微調整モデル ↗を作成します。
OpenAIのAPIのこの機能を使用すると、カスタム指示と例の回答のセットに基づいて、OpenAIのさまざまな大規模言語モデルからカスタムモデルを導出できます。これらの指示と例の回答は、微調整ドキュメントとして知られる文書に記述されます。この文書はR2に保存され、新しい微調整モデルを作成する際にOpenAIのAPIに動的に提供されます。
この機能を使用するには、次のタスクを実行します。
- 微調整ドキュメントをR2にアップロードします。
- R2ファイルを読み取り、OpenAIにアップロードします。
- ドキュメントに基づいて新しい微調整モデルを作成します。
このアプリケーションの完成したコードを確認するには、このチュートリアルのGitHubリポジトリ ↗を参照してください。
始める前に、次のものを用意してください。
- R2にアクセスできるCloudflareアカウント。Cloudflareアカウントを持っていない場合は、サインアップ ↗してから続行してください。その後、CloudflareダッシュボードからR2を購入します。
- OpenAI APIキー。
- JSON Lines ↗形式で構造化された微調整ドキュメント。ソースコード内のサンプルドキュメント ↗を使用してください。
まず、c3 CLIを使用して新しいCloudflare Workersプロジェクトを作成します。
npm create cloudflare@latest -- finetune-chatgpt-modelyarn create cloudflare@latest finetune-chatgpt-modelpnpm create cloudflare@latest finetune-chatgpt-modelFor setup, select the following options:
- For What would you like to start with?, choose
Hello Worldの例. - For Which template would you like to use?, choose
Hello World Worker. - For Which language do you want to use?, choose
TypeScript. - For Do you want to use git for version control?, choose
Yes. - For Do you want to deploy your application?, choose
No(we will be making some changes before deploying).
上記のオプションは、「Hello World」TypeScriptプロジェクトを作成します。
新しく作成したディレクトリに移動します:
cd finetune-chatgpt-model次に、微調整ドキュメントをR2にアップロードします。R2は、Workersアプリケーション内でファイルを保存および取得できるキー-バリューストアです。Wranglerを使用して新しいR2バケットを作成します。
新しいR2バケットを作成するには、wrangler r2 bucket createコマンドを使用します。Cloudflareアカウントにログインしていることを確認してください。Wranglerでログインしていない場合は、wrangler loginコマンドを使用します。
npx wrangler r2 bucket create <BUCKET_NAME><BUCKET_NAME>を希望するバケット名に置き換えます。バケット名は小文字でなければならず、ダッシュのみを含むことができます。
次に、wrangler r2 object putコマンドを使用してファイルをアップロードします。
npx wrangler r2 object put <PATH> -f <FILE_NAME><PATH>は、アップロードしたいファイルのバケットとファイルパスの組み合わせです。たとえば、fine-tune-ai/finetune.jsonlのように、fine-tune-aiがバケット名です。<FILE_NAME>を微調整ドキュメントのローカルファイル名に置き換えます。
バインディングは、WorkerがR2バケットなどの外部リソースと対話する方法です。
R2バケットをWorkerにバインドするには、wrangler.tomlファイルに次の内容を追加します。バインディングプロパティを有効なJavaScript変数識別子に更新します。<YOUR_BUCKET_NAME>をステップ2で作成したバケットの名前に置き換えます。
[[r2_buckets]]binding = 'MY_BUCKET' # <~ 有効なJavaScript変数名bucket_name = '<YOUR_BUCKET_NAME>'Hono ↗を使用します。これは、Cloudflare Workersアプリケーションを構築するための軽量フレームワークです。Honoは、ルートとミドルウェア関数を定義するためのインターフェースを提供します。プロジェクトディレクトリ内で、次のコマンドを実行してHonoをインストールします。
npm install honoまた、OpenAI Node APIライブラリ ↗をインストールする必要があります。このライブラリは、Node.jsプロジェクト内でOpenAI REST APIに便利にアクセスするためのものです。ライブラリをインストールするには、次のコマンドを実行します。
npm install openai次に、src/index.tsファイルを開き、デフォルトのコードを以下のコードに置き換えます。<MY_BUCKET>をwrangler.tomlファイルで設定したバインディング名に置き換えます。
import { Context, Hono } from "hono";import OpenAI from "openai";
type Bindings = { <MY_BUCKET>: R2Bucket OPENAI_API_KEY: string}
type Variables = { openai: OpenAI}
const app = new Hono<{ Bindings: Bindings, Variables: Variables }>()
app.use('*', async (c, next) => { const openai = new OpenAI({ apiKey: c.env.OPENAI_API_KEY, }) c.set("openai", openai) await next()})
app.onError((err, c) => { return c.text(err.message, 500)})
export default app;上記のコードでは、最初に必要なパッケージをインポートし、型を定義します。次に、appを新しいHonoインスタンスとして初期化します。useミドルウェア関数を使用して、すべてのルートのコンテキストにOpenAI APIクライアントを追加します。このミドルウェア関数を使用すると、任意のルートハンドラー内からクライアントにアクセスできます。onError()は、エラーハンドラーを定義し、エラーをJSONレスポンスとして返します。
このセクションでは、ファイルアップロードを処理するルートと関数を定義します。
createFileでは、WorkerがR2からファイルを読み取り、Fileオブジェクトに変換します。次に、WorkerはOpenAI APIを使用してファイルをアップロードし、レスポンスを返します。
GET /filesルートは、R2にアップロードされた微調整ドキュメントのファイル名を表すクエリパラメータfileを持つGETリクエストをリッスンします。この関数は、ファイルアップロードプロセスを管理するためにcreateFile関数を使用します。
<MY_BUCKET>をwrangler.tomlファイルで設定したバインディング名に置き換えます。
// ファイルの先頭に新しいインポートを追加import { toFile } from 'openai/uploads'
const createFile = async (c: Context, r2Object: R2ObjectBody) => { const openai: OpenAI = c.get("openai")
const blob = await r2Object.blob() const file = await toFile(blob, r2Object.key)
const uploadedFile = await openai.files.create({ file, purpose: "fine-tune", })
return uploadedFile}
app.get('/files', async c => { const fileQueryParam = c.req.query("file") if (!fileQueryParam) return c.text("ファイルクエリパラメータがありません", 400)
const file = await c.env.<MY_BUCKET>.get(fileQueryParam) if (!file) return c.text("ファイルが見つかりませんでした", 400)
const uploadedFile = await createFile(c, file) return c.json(uploadedFile)})このセクションには、GET /modelsルートとcreateModel関数が含まれています。createModel関数は、詳細を指定し、OpenAIとの微調整プロセスを開始します。このルートは、新しい微調整モデルを作成するための受信リクエストを処理します。
const createModel = async (c: Context, fileId: string) => { const openai: OpenAI = c.get("openai");
const body = { training_file: fileId, model: "gpt-4o-mini", };
return openai.fineTuning.jobs.create(body);};
app.get("/models", async (c) => { const fileId = c.req.query("file_id"); if (!fileId) return c.text("ファイルIDクエリパラメータがありません", 400);
const model = await createModel(c, fileId); return c.json(model);});このセクションでは、GET /jobsルートと対応するgetJobs関数について説明します。この関数は、OpenAIのAPIと対話してすべての微調整ジョブのリストを取得します。このルートは、この情報を取得するためのインターフェースを提供します。
const getJobs = async (c: Context) => { const openai: OpenAI = c.get("openai"); const resp = await openai.fineTuning.jobs.list(); return resp.data;};
app.get("/jobs", async (c) => { const jobs = await getJobs(c); return c.json(jobs);});Workerアプリケーションを作成し、必要な関数を追加したら、アプリケーションをデプロイします。
デプロイする前に、アプリケーションのためにOPENAI_API_KEY シークレットを設定する必要があります。次のwrangler secret putコマンドを実行してこれを行います。
npx wrangler secret put OPENAI_API_KEYCloudflareのグローバルネットワークにWorkerアプリケーションをデプロイするには:
- Workerプロジェクトのディレクトリにいることを確認し、次の
wrangler deployコマンドを実行します:
npx wrangler deploy-
Wranglerがコードをパッケージ化してアップロードします。
-
アプリケーションがデプロイされた後、WranglerはWorkerのURLを提供します。
アプリケーションを使用するには、以前にアップロードしたファイル名と一致するfileクエリパラメータを持つリクエストを/filesに送信して新しい微調整ジョブを作成します:
curl https://your-worker-url.com/files?file=finetune.jsonlファイルがアップロードされたら、/modelsにもう一度リクエストを発行し、file_idクエリパラメータを渡します。これは、/filesルートからJSONとして返されたidと一致する必要があります:
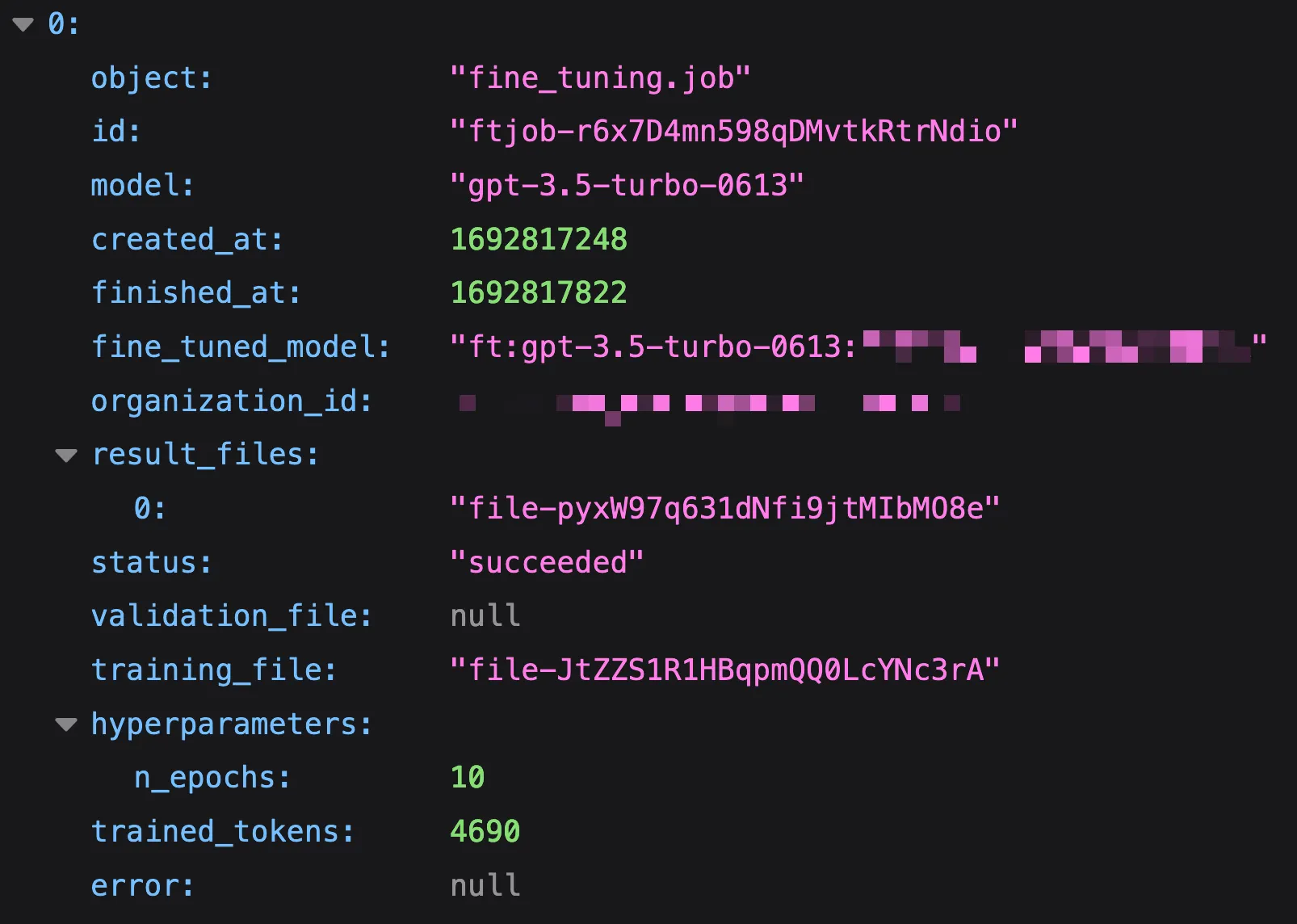
curl https://your-worker-url.com/models?file_id=file-abc123最後に、/jobsを訪れてOpenAIの微調整ジョブのステータスを確認します。微調整ジョブが完了すると、fine_tuned_model値が表示され、微調整されたモデルが作成されたことを示します。
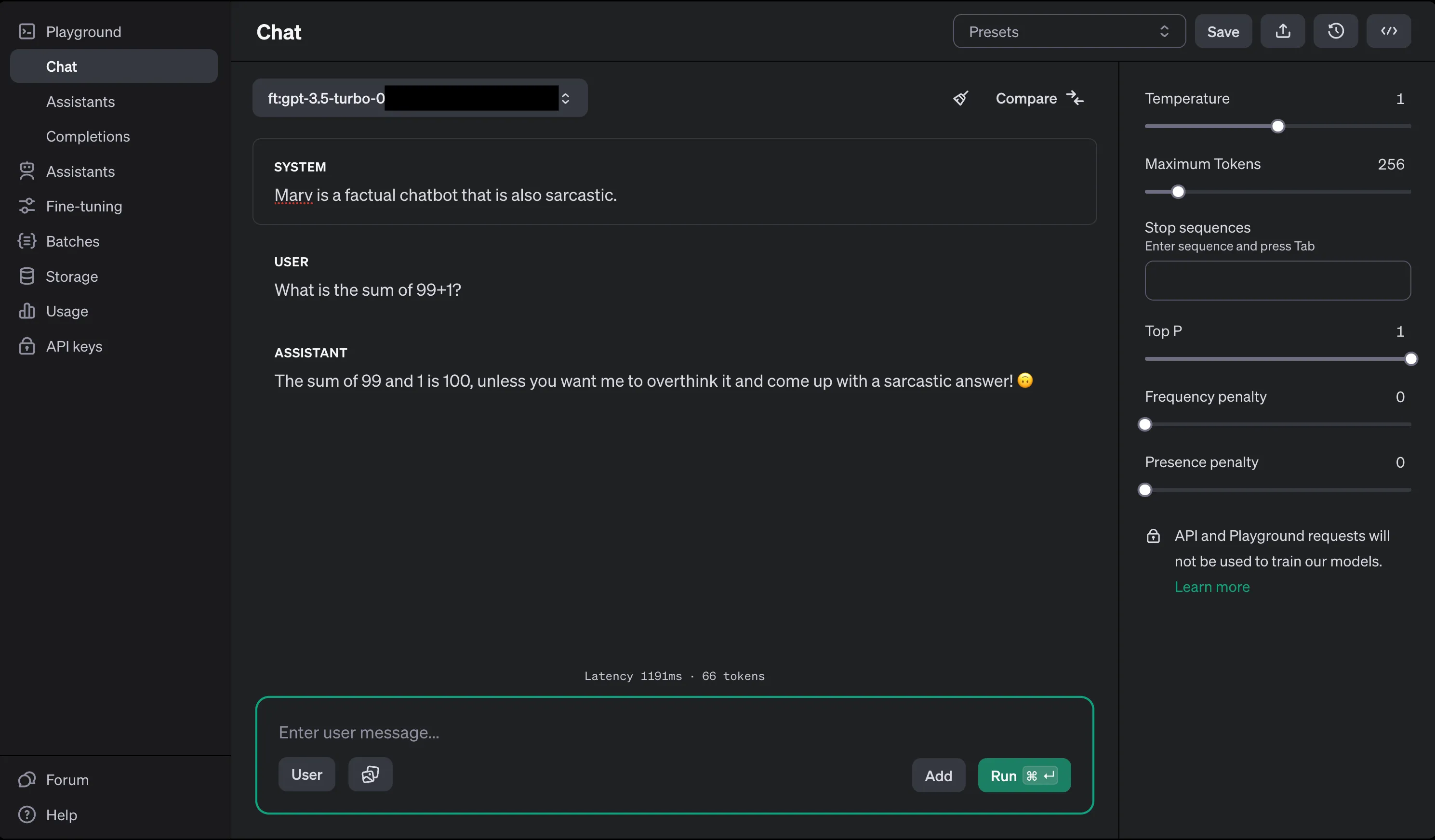
微調整モデルを使用するには、OpenAI Playground ↗を訪れて、インターフェースの左上のドロップダウンから微調整モデルを選択します。
OpenAIのチャット完了エンドポイントへのAPIリクエストで使用します。たとえば、以下のコード例のように:
openai.chat.completions.create({ messages: [{ role: "system", content: "あなたは役に立つアシスタントです。" }], model: "ft:gpt-4o-mini:my-org:custom_suffix:id",});Workersを使用してさらに構築するには、チュートリアルを参照してください。
質問がある場合、支援が必要な場合、またはプロジェクトを共有したい場合は、Cloudflare開発者コミュニティに参加して、他の開発者やCloudflareチームとつながりましょう。Discord ↗でお待ちしています。